
¿Qué controla realmente la norma de pesos en Grokking?
Descubre cómo la escala de logits, y no la norma de pesos, determina el retraso en Grokking. Un estudio revela que el 97% del efecto depende de la saturación
Descubre cómo la escala de logits, y no la norma de pesos, determina el retraso en Grokking. Un estudio revela que el 97% del efecto depende de la saturación

Descubre cómo la nueva pérdida GKL mejora la robustez adversarial y la destilación de conocimiento, logrando resultados líderes en RobustBench.

El descubrimiento de programas no es imposible, tiene un costo medible: el conocimiento estructural se intercambia directamente con el esfuerzo de búsqueda. Conoce el teorema.

Descubre cómo el desacuerdo entre modelos de IA permite detectar errores sin etiquetas. Un método simple y sin entrenamiento que supera a las técnicas tradicionales.

Explora un nuevo marco teórico de campo medio para la auto-atención multicabezal, estableciendo condiciones de convergencia y estabilidad bajo entrenamiento con entropía cruzada.
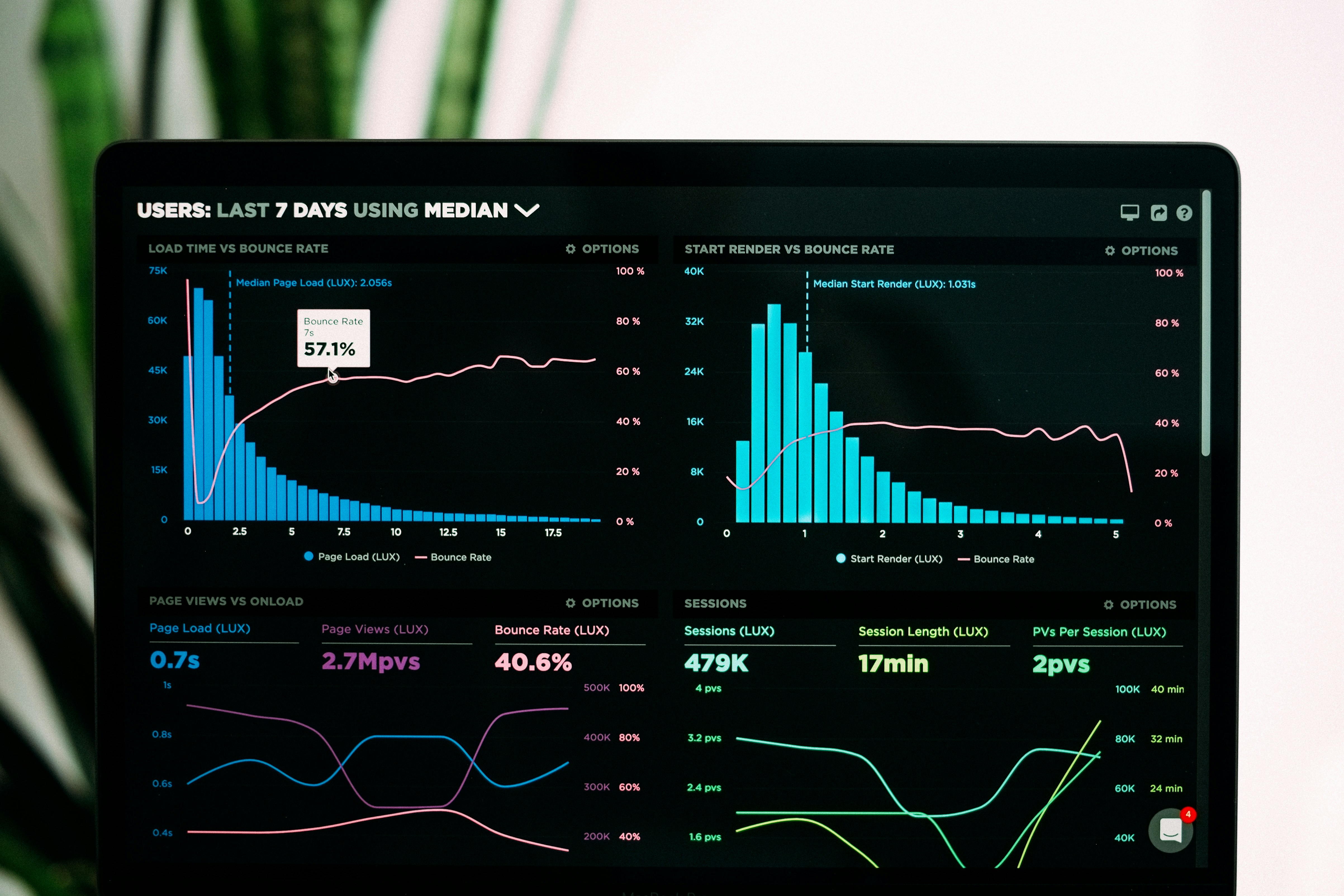
¿Por qué la pérdida de histograma mejora la regresión? Investigamos sus beneficios: optimización, no información extra. Aplicable sin costoso ajuste de hiperparámetros.

Descubre DistIL: aprendizaje por refuerzo con retroalimentación rica para razonamiento, código y matemáticas. ¡Lee más!

Descubre cómo el borde de estabilidad redistribuye el aprendizaje entre grupos de datos, beneficiando a unos y suprimiendo a otros.